
A simple approach to building a real-time collaborative text editor
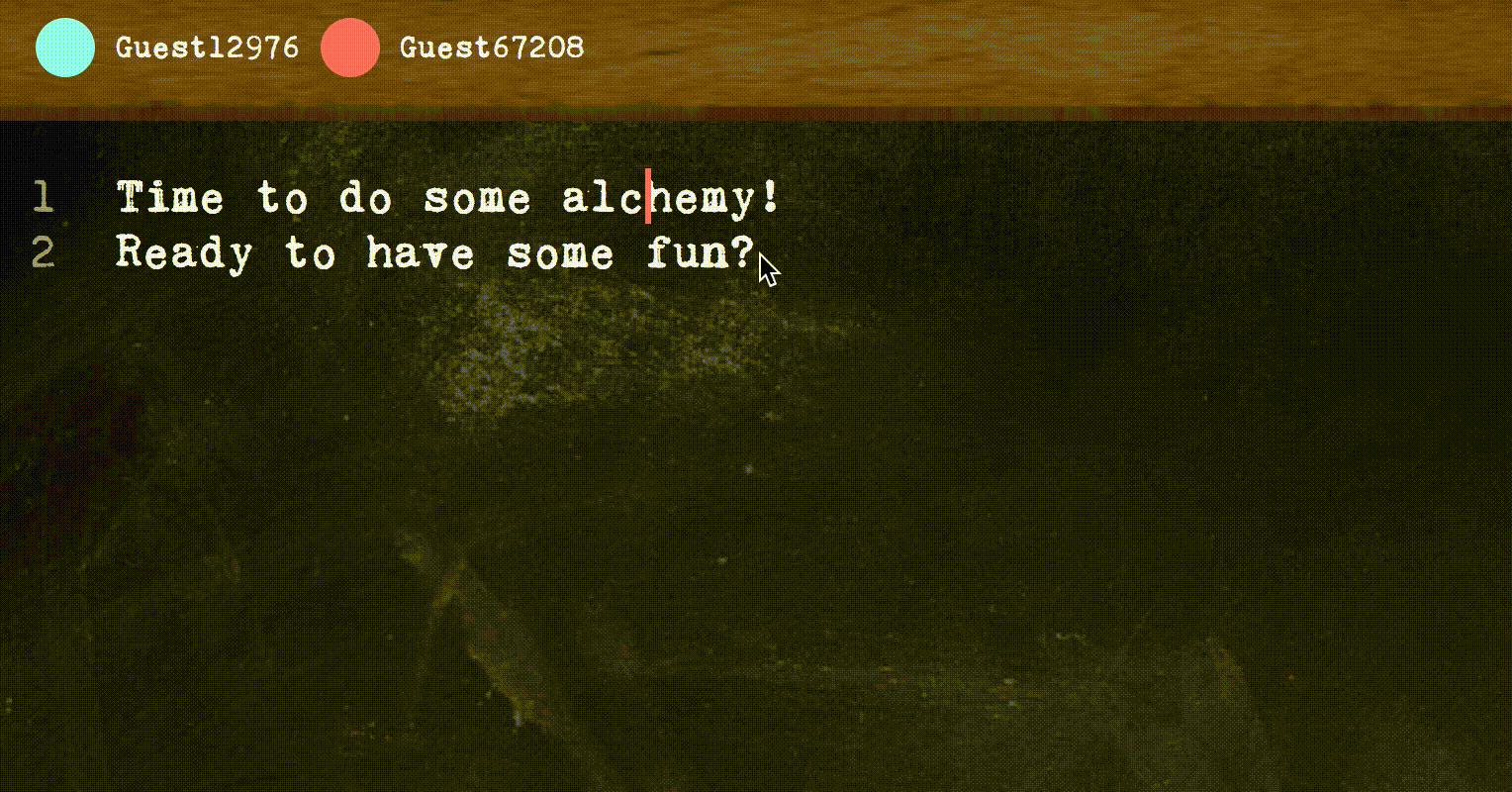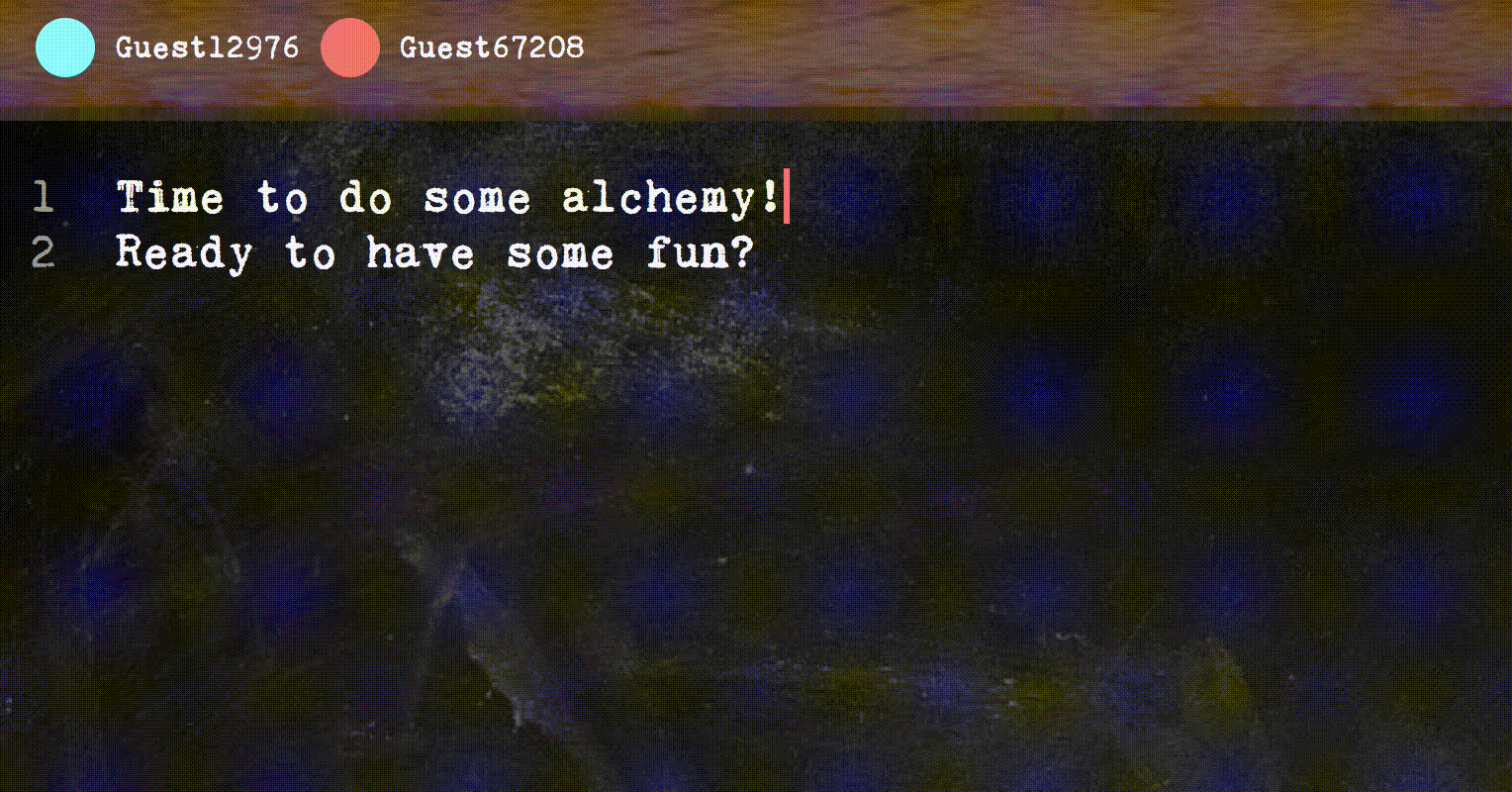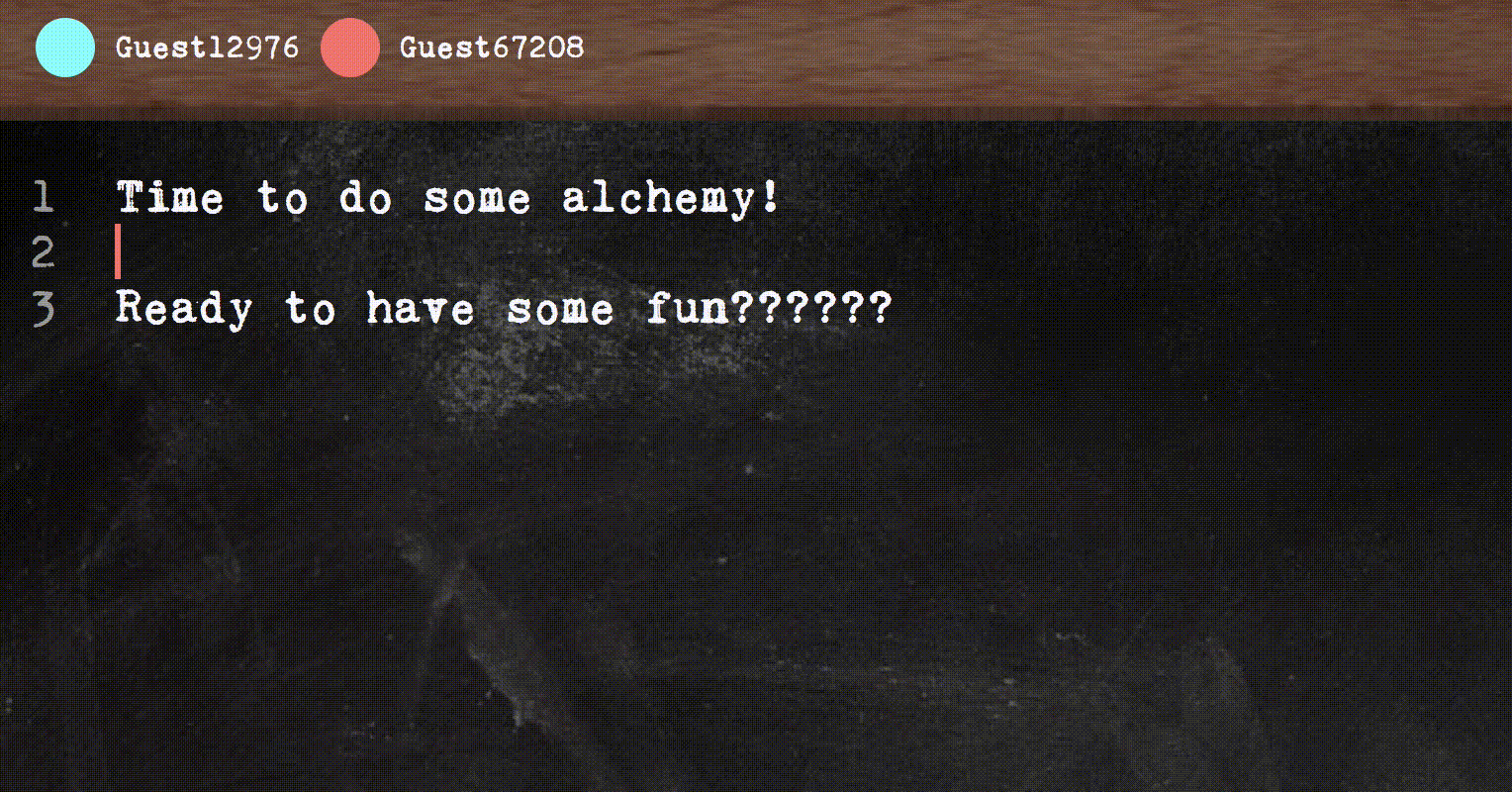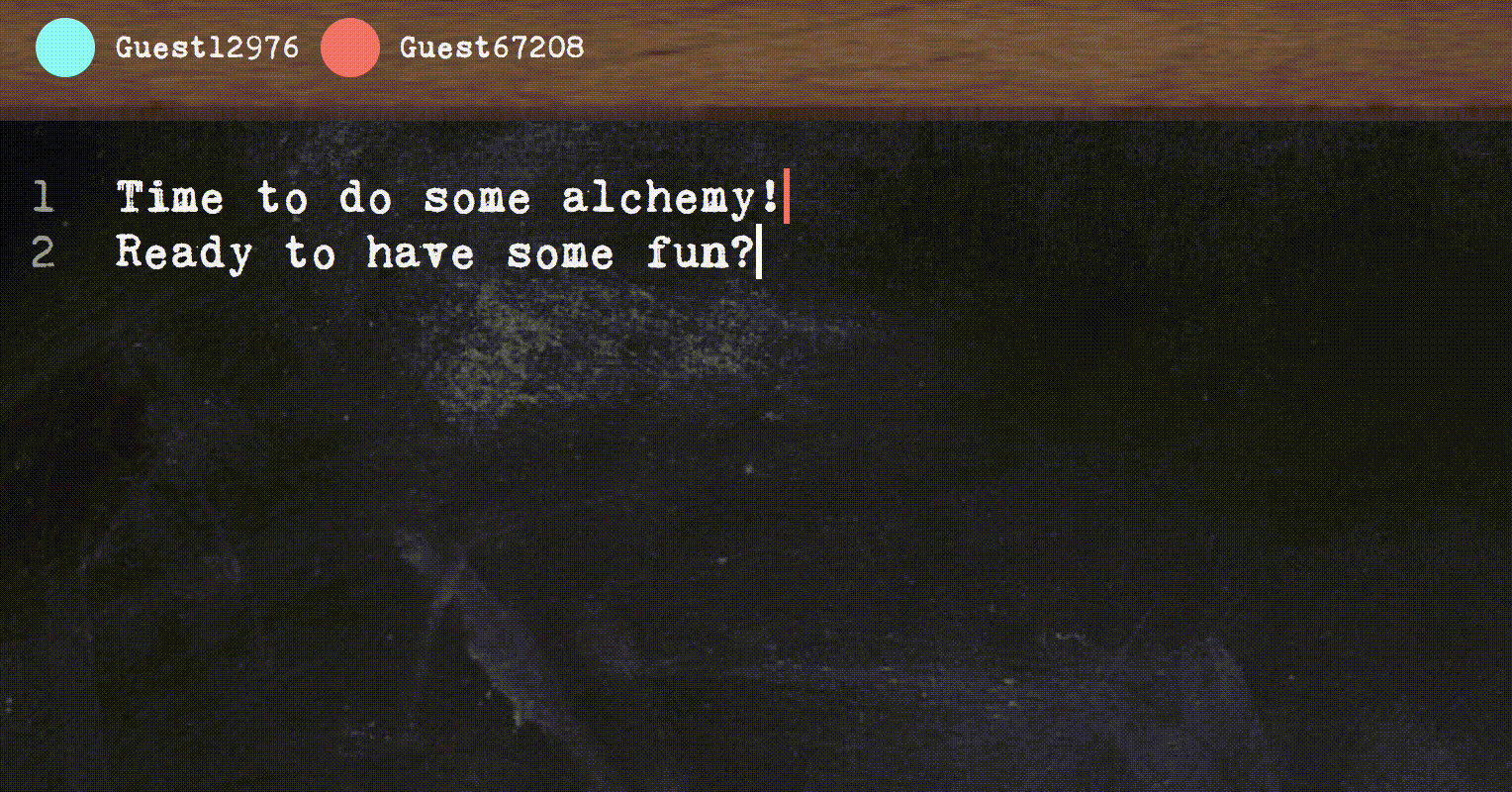
This post is my attempt to write an easy to understand introduction to the main ideas behind building a real-time collaborative text editor, which can be tricky as you want all clients to synchronize and see a sensible result even in the face of concurrent edits.
In some ways, this is already a solved problem by Operational Transform (OT) and open-source implementations like Firepad and ShareJS. So if you want a plug-in-play solution, use one of those and move along. I decided to use a CRDT (Conflict-Free Replicated Data Type), a newer technique (more specifically, I adapted Logoot). There are technical pros and cons versus OTs that I’m not gonna bore you with, but for me the major advantage of the CRDT approach is that it’s simpler to understand and to convince yourself that it works (and thus, to maintain it).
I hope to demonstrate that in this post by splitting the problem of implementing a CRDT into multiple conceptual layers. Those layers should be fairly easy to understand one at a time. In contrast, OTs work by requiring you to handle every combination of operations arriving in different orders (i.e. all the weird shit users do) and proving that you’ve handled all of the edge cases. While the code itself may not be that complicated, if you make a mistake, you’re screwed.
This was a fun side project to build while at Recurse Center, and also quite relevant now that applications are increasingly moving to the web and becoming collaborative. Good ol’ Google Docs showed that it’s quite useful for multiple people to be able to edit at the same time. Now, Dropbox Paper, Overleaf, Coderpad, etc all support collaborative writing.
The problem of synchronization
First, I’ll briefly introduce what makes collaborative text editor hard. Let’s say you have two students, Ping and Pong working together on the same essay, and they’re working on different parts of the document. Ping makes a change: insert the string “, sadface” at the end of the line. The naive way in which Ping’s editor could transmit the change to Pong’s editor is just to send a message insert(", sadface", col=44).

And this would work if changes could be transmitted and applied instantaneously (possibly breaking causality along the way).
In practice, Ping’s neighbor is torrenting The Emoji Movie (don’t ask me why) and causing Ping’s messages to arrive really slowly to Pong. While Ping’s message was stuck in emoji traffic, Pong added the string “, not” at column 23.

Wops. By the time insert(", sadface", col=44) arrives, the end of the line is no longer column 44. We still insert though, and get this:

Now, we’re in an inconsistent state and The Matrix falls apart around Ping and Pong.
Commute + idempotent => synchronize
Let’s look at the first insight that’ll allow us to make a collaborative text editor.
In the previous example, two operations were generated concurrently on different clients. When we send them over to the other client, they end up applied in different orders and the clients end up in different states. They don’t commute.

On the other hand, if every operation could commute with every other operation, the clients would converge to the same state regardless of which messages arrived where first. You still need to require that operations commute in a way that makes sense to the user of course. Lest you get a lazy programmer that makes every operation delete the whole file. “Hey, the states were the same in the end!” 🙄. But otherwise, if operations commute, synchronization is trivially easy. A basic example is an add-only set. It doesn’t matter the order in which you add things to the set, the set is the same in the end.

While commutativity captures 90% of the idea, in practice we need another condition for synchronization, which is that operations need to be idempotent. That is, you can apply the operation twice and it’ll give you the same result as applying it once. This is useful not only if your messages get duplicated somehow (maybe you’re using UDP instead of TCP? I dunno) but also if two clients decide to do the same operation at the same time. Then, receiving the other client’s (now duplicate) operation should be a no-op (do nothing).
I’m using the term “commute” loosely here. In practice you don’t need your operations to commute in the sense that EVERY operation commutes with EVERY other operation. It’s great if they do since commutativity is a sufficient condition for convergence, but it’s not a necessary condition. For instance, it doesn’t make sense to reorder operations generated by one client because you might end up putting DELETE(X) before CREATE(X). What we really want is some sort of “interleave-ability” defined by the causal order between operations and have the merging obey some partial order. But the goal of this post is to provide an intuition, even if at the expense of correct technicality. I’ll refer you to the CRDT papers for the big words.
Make everything (all kiwis 🥝) unique
At a very abstract level, a CRDT is just a data structure and a set of operations on the data structure that commute with each other. There’s lots of different examples of CRDTs. Some quite simple that you can read about while having breakfast. Others, well, less so.
Before we get into text editing, which is one of the less simple CRDTs, let’s create a simple CRDT to help us gain some intuition. We’re going to build a bag, also known a multiset. Like the name implies, it’s a collection in which you can put and retrieve objects. It’s like a Set, but it can contain multiple copies of the same element.
The two main operations on a Bag that we’re concerned with are:
- Add(x)
- Remove(x)
You probably also want to iterate over the Bag, count elements, etc, but those do not modify the Bag therefore don’t need synchronization.
Add and remove are not commutative. Imagine that Ping, Pong and Pang all have an instance of a bag that contains a kiwi (i.e. 🥝).
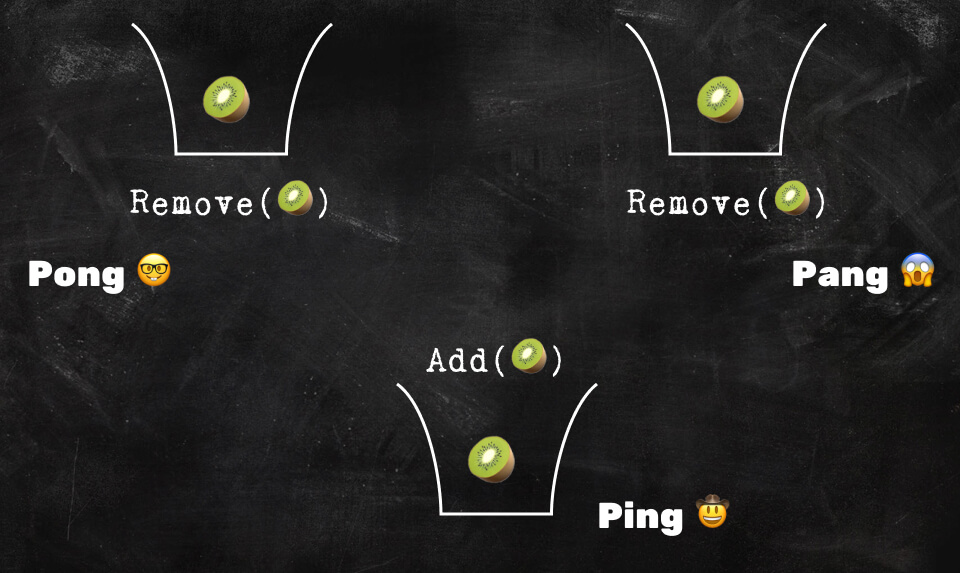
Simultaneously, Ping puts in another kiwi, Pong removes the kiwi and Pang removes a kiwi. What happens?
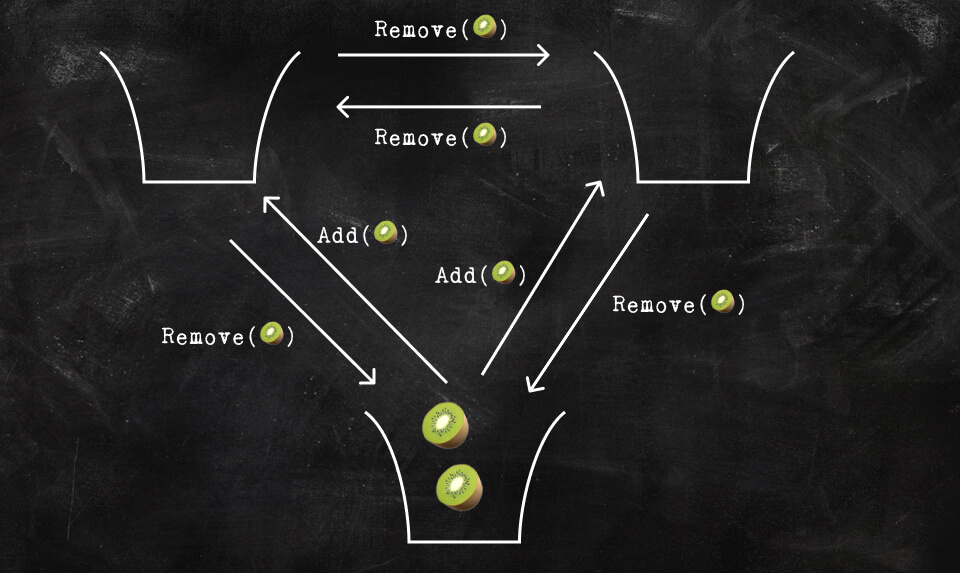
The fact that both Pong and Pang both decided to remove a Kiwi from the bag at once is not a problem (although jeez, Pong, Pang, why did you have to do that?). Remember, operations are idempotent and the end result should just be that the kiwi got removed from the bag. The problem is that Ping has two kiwis in his bag (🥝🥝) when receiving the two DELETE(🥝) messages from Pong and Pang so Ping deletes both kiwis 🥝🥝. In the meantime, Pong and Pang will end up with either one kiwi 🥝 or no kiwi 🥝 depending on whether ADD(🥝) or DELETE(🥝) arrived first.
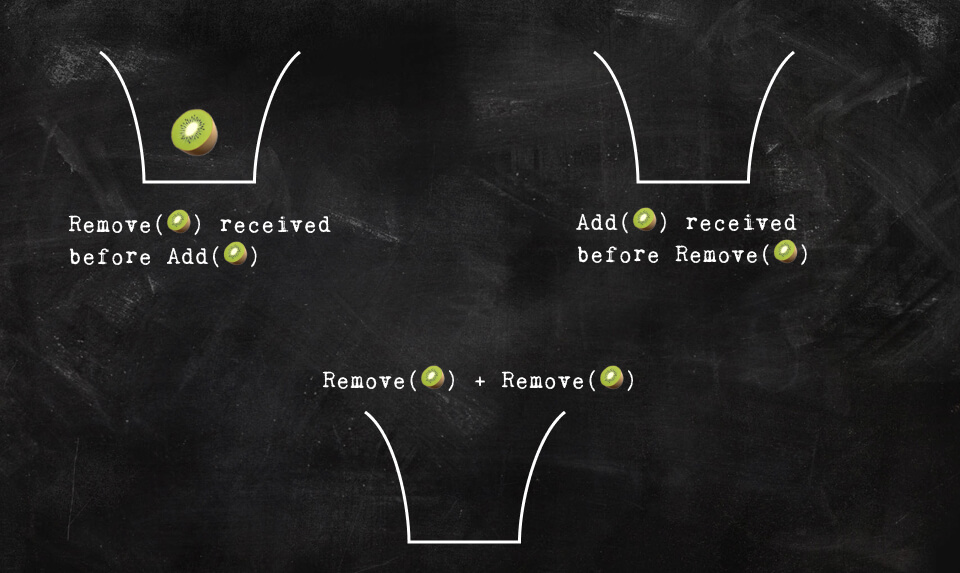
It’s The Kiwipocalypse 💥🥝🔥.
We can fix this by changing the semantics of the operation a little. Now, not only are kiwis 🥝 a unique fruit different from other fruits 🍓🍌🍏, but we’ll make every kiwi unique. I’m calling this The Kiwi Manifesto 🥝. More specifically, we’ll assign each individual fruit a unique ID when created.
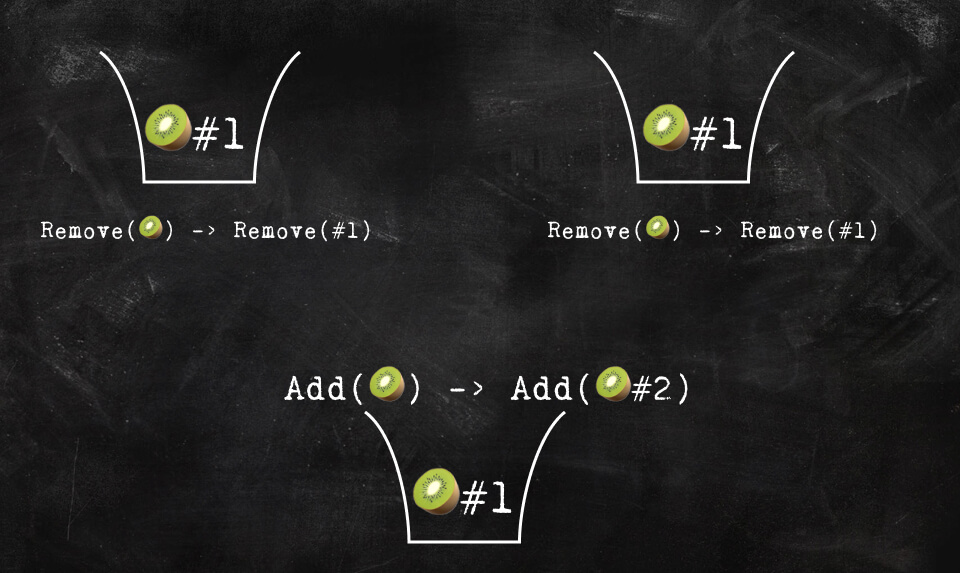
The programmer will modify the Bag in the same way with ADD(🥝) and REMOVE(🥝). But the operation that will get sent to other clients will be ADD(🥝, <unique id>) and REMOVE(<unique id>). When adding a fruit to the bag, a globally unique id that has never been used before (in any client, ever) gets created and assigned to the fruit. When removing a fruit from the bag, the remove operation will remove the fruit from the local bag, get the removed fruit’s unique id, and send a message to other clients to remove an item in the bag with that unique id. Not exposing the unique id to the user also makes sure that they can’t ask to delete a kiwi that doesn’t exist yet.
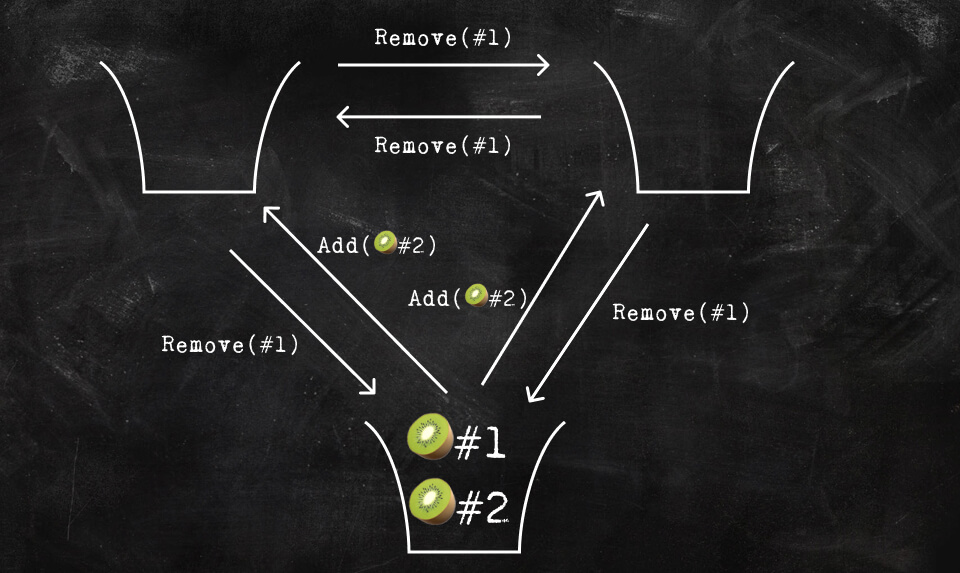
This should make intuitive sense. Now, the delete message isn’t just about deleting a kiwi, it’s about deleting that kiwi. And you no longer run into ordering problems.

Finally, how do you generate new, globally unique ids? You need consensus between clients, so implement Paxos. Just kidding. Assuming that all clients have a unique identifier, make it part of the new object’s unique id. This makes sure that objects created in different clients are distinguishable without needing them to communicate with each other. To make sure that objects created by the same client are distinguishable, create a counter on each client that increments the bag is modified and add it to the unique id. In summary each object is tagged with (client id, counter).
Text editing: order in the fruit kingdom
Alright, but you say, “that’s cool, but I didn’t come here to build fruit baskets, I want to make a text editor”. Fine, fine.
A text document is not that different from a Bag (a bag of Alpha-Bit cereals anybody?). There’s a bunch of characters that you can add and delete. It’s just that the problem is a bit harder because each character has a position. That’s one way to look at it. Another way that’ll be more helpful to us is to say that a text document is an ordered bag of characters. The position of the characters then simply follow from that order (even if there’s newlines, those are just a “\n” character).

So what is the order going to be? What we’re going to try to do in this section and the next section is to design a way of generating unique ID for characters such that the sort order of those ID will tell us the order of those character in the document.
To do this, let’s first think about how we would insert characters in a line where all the existing characters have already been assigned unique IDs. Suppose our IDs were just integers, and we sorted characters by increasing ID. We might have something like this:
o c c u r e n c e
1 4 6 7 8 9 10 11 12
Wait that’s not how occurence occurrence is spelled. Spelling occurrence is hard ok? Anyway let’s fix that by adding an “r” between (“r”, 8) and (“e”, 9). But there’s no room! I guess we’re stuck with this spelling now.
Or not. A natural thing to do would just to create a fractional index between 8 and 9. If we insert the character (“r”, 8.5), then we get the expected result:
o c c u r r e n c e
1 4 6 7 8 8.5 9 10 11 12
Therefore, we could use floats instead of integers to store our character IDs. In practice, we would want to store a list of integer representing the digits after the fraction so we don’t ever run out of precision. There’s also no need to have indices > 1 if we’re going to have fractional indices anyway, so we’ll just store the fractional digits.
Fractional indices by themselves of course are not globally unique IDs. Our IDs will need to be a bit more clever than that to be unique like snowflakes ❄️.
No two characters are the same
To generate globally unique IDs which I will now call position identifiers (since they identify stuff and position stuff), there’s two situations that we need to handle:
- Two clients generating the same ID at the same time (e.g. insert a character at the same position concurrently)
- One client generating an ID that was already generated (e.g. delete a character and reinsert it)
Here’s the high level idea on how we’re going to solve this. Assume all clients have a unique site ID. We’re still going to use fractional indices, but every time we insert a character and add or change a digit in a fraction, we’ll tag the digit with the site ID at which it was inserted.
This is how it looks like. Say that whale 🐋 starts a document with “my hero” and water buffalo 🐃 enters that same document.
m [(1, 🐋)]
y [(2, 🐋)]
_ [(3, 🐋)]
h [(4, 🐋)]
e [(5, 🐋)]
r [(6, 🐋)]
o [(7, 🐋)]
If water buffalo adds “super”, then the document might look like this:
m [(1, 🐋)]
y [(2, 🐋)]
_ [(3, 🐋)]
s [(3, 🐋), (1, 🐃)]
u [(3, 🐋), (2, 🐃)]
p [(3, 🐋), (3, 🐃)]
e [(3, 🐋), (4, 🐃)]
r [(3, 🐋), (5, 🐃)]
h [(4, 🐋)]
e [(5, 🐋)]
r [(6, 🐋)]
o [(7, 🐋)]
If whale accidentally hits the keyboard and adds a bunch of “u”s (whales have fat fingers, I read it on Wikipedia), then it could look like this.
m [(1, 🐋)]
y [(2, 🐋)]
_ [(3, 🐋)]
s [(3, 🐋), (1, 🐃)]
u [(3, 🐋), (2, 🐃)]
u [(3, 🐋), (2, 🐃), (1, 🐋)]
u [(3, 🐋), (2, 🐃), (2, 🐋)]
p [(3, 🐋), (3, 🐃)]
e [(3, 🐋), (4, 🐃)]
r [(3, 🐋), (5, 🐃)]
h [(4, 🐋)]
e [(5, 🐋)]
r [(6, 🐋)]
o [(7, 🐋)]
And so it went on, and a friendship between whales and water buffalos was formed!🐋!🐃! By making sure that the last digit of any newly added character’s position identifier is always tagged with the site ID, two clients can never conflict just by adding new characters.
You might think every position identifier could just contain a single site ID instead of a site ID for every digit, but you do need to tag every digit with a site ID. As we’ll see later, the sort order depends on the site ID so some site IDs need to be preserved to make sure that we’re inserting at the right place.
Finally, to handle the case of a client deleting and reinserting the same character (I know it’s you, silly monkey 🙈), every client gets a counter that always increments anytime an action happens. A simple integer counter suffices if you have a central server though the Logoot paper suggests using a Lamport Timestamp which is only two lines of arithmetic anyway.
Deleting characters is simply a DELETE(position identifier) operation, just like in the fruit bag example.
Now that we got:
- Globally unique IDs with the CREATE operation
- CREATE and DELETE commute
- The sort order of the ID defines what the order of the character is to represent text
We got a collaborative, synchronized text editor! Well, mostly that’s true. I guess I should talk about some implementations details.
Show me ze money  (ze code)
(ze code)
Up to this point, I’ve been handwaving over all the details to give you an intuition of how this CRDT works. But those details are kind of important to make sure we’ve covered all edge cases. I recommend also reading the Logoot paper for completeness. It’s a pretty readable paper. Note that I’ll be using similar, but slightly different terminology at places for ease of presentation. Let’s start with a proper definition of a position identifier.
- A position identifier generated at site \( s \) is a tuple (position, \( clock_s \)) where the \( clock(s) \) is the Lamport clock value at site \( s \)
- A position is a list of identifiers
- An identifier is a tuple (digit, site id) where digit and site id are integers
The digits can be in any base you want. I personally use 256 and convert the number to a string for ease of debugging, but other reasonable choices include MAX_INT, Base64, Base85, etc. Note also that for simplicity, each position is between 0 and 1 insofar as the digits are concerned, so we can think of a position as \( p = 0.p_1p_2p_3… \) where \( p_i \) are identifiers and we don’t need to store anything left of the decimal.
In code, the data structures look like this:
class Identifier {
digit: number
site: number
}
class Char {
position: Identifier[]
lamport: number
value: string
}
Next, we need to define the sort order between the position identifiers. Note that the clock value \( clock_s \) is not used for sorting since a client will never insert a character with the same position as another unless that character has already been deleted. So we’re really just defining the sort order between positions, which I implemented as such:
function comparePosition(p1: Identifier[], p2: Identifier[]): number {
for (let i = 0; i < Math.min(p1.length, p2.length); i++) {
const comp = Identifier.compare(p1[i], p2[i]);
if (comp !== 0) {
return comp;
}
}
if (p1.length < p2.length) {
return - 1;
} else if (p1.length > p2.length) {
return 1;
} else {
return 0;
}
}
function compareIdentifier(i1: Identifier, i2: Identifier) {
if (i1.digit < i2.digit) {
return -1;
} else if (i1.digit > i2.digit) {
return 1;
} else {
if (i1.site < i2.site) {
return -1;
} else if (i1.site > i2.site) {
return 1;
} else {
return 0;
}
}
}
This sort order is more or less what you’d expect, sorting by the digits and using sites as tiebreakers. You may refer to the paper for the formal definition and to make sure I didn’t make any mistakes. It’s worth making sure you really understand the sort order, because it affects how we insert characters. In particular, having sites as tiebreakers means you can have a sorted list of positions that looks like this:
[(1, 0)] 0.1
[(1, 0), (4, 0)] 0.14
[(1, 0), (6, 0), (3, 1)] 0.163
[(1, 0), (7, 0)] 0.17
[(1, 1)] 0.1
[(1, 1), (1, 1)] 0.11
Generating new position identifiers on insertion is more complex. I’ll describe what I came up with but be warned, while I made sure to write tests, this has not been tested in large production systems.
The algorithm described in Logoot is not suitable for our use case. In addition to missing what I think are key details on how to handle certain edge cases, the original paper was written for synchronizing individual lines, whereas a real-time collaborative editor needs to synchronize individual characters. Furthermore, when writing text documents, 99% of character insertions are going to happen on the right side of the last inserted character, with only occasional cursor jumps. We need to take this into account when creating position identifiers. Technically position identifiers are unbounded in size, but we can try to not make them grow too fast. If we were to naively, say, generate a position identifier halfway between two characters, the size of the position identifiers would grow very fast.
We can’t just do arithmetic on positions as arbitrary precision numbers because when two digits are the same, the sites could still be different. In the example above, we saw how this can lead to positions not being sorted in the same way numbers would be sorted.
Furthermore, as the “gap” in position between two characters gets smaller, we need to create smaller increments in position.
Because this algorithm is intricate, I’ll start with the code and explain how to think about it:
function generatePositionBetween(position1: Identifier.t[],
position2: Identifier.t[],
site: number): Identifier.t[] {
// Get either the head of the position, or fallback to default value
const head1 = head(position1) || Identifier.create(0, site);
const head2 = head(position2) || Identifier.create(Decimal.BASE, site);
if (head1.digit !== head2.digit) {
// Case 1: Head digits are different
const n1 = Decimal.fromIdentifierList(position1);
const n2 = Decimal.fromIdentifierList(position2);
const delta = Decimal.subtractGreaterThan(n2, n1);
// Increment n1 by some amount less than delta
const next = Decimal.increment(n1, delta);
return Decimal.toIdentifierList(next, position1, position2, site);
} else {
if (head1.site < head2.site) {
// Case 2: Head digits are the same, sites are different
return cons(head1,
generatePositionBetween(rest(position1), [], site));
} else if (head1.site === head2.site) {
// Case 3: Head digits and sites are the same
return cons(head1,
generatePositionBetween(rest(position1), rest(position2), site));
} else {
throw new Error("invalid site ordering");
}
}
}
generatePositionBetween is a function that recursively examines the most significant digits of an identifier by handling three different cases.
Case 1: Head digits are different
beforePosition = [(1, x), ...]
afterPosition = [(2, y), ...]
This is the base case. If the most significant digits of the before and after positions differ, than it is possible to generate a new position such that beforePosition < newPosition < afterPosition regardless of the values of the sites x and y, simply by incrementing the digits of beforePosition by a small amount less than (afterPosition - beforePosition). Therefore, in this case, we first convert the positions to a decimal representation by dropping the sites.
// In module 'decimal'
export type t = number[]
function fromIdentifierList(identifiers: Identifier.t[]): t {
return identifiers.map(ident => ident.digit);
}
The arithmetic operations add and subtractGreaterThan simply implement textbook addition and subtraction and you may refer to the source code for an implementation. The increment operation, on the other hand, is a bit more tricky.
function increment(n1: t, delta: t): t {
const firstNonzeroDigit = delta.findIndex(x => x !== 0);
const inc = delta.slice(0, firstNonzeroDigit).concat([0, 1]);
const v1 = add(n1, inc);
const v2 = v1[v1.length - 1] === 0 ? add(v1, inc) : v1;
return v2;
}
All this does it increment a digit of n1 by 1 such that the increment is less than delta. Another tricky bit of increment is that we want to make sure that the result of increment does not have a 0 as the last digit. Why? Because then we would have to later make sure that we’re able to generate positions between two ambiguous representations of the same decimal (e.g. 0.201 and 0.2010). The simple trick used here is to increment again if that happens.
When we’re done generating a new decimal position, we convert it back into a position by assigning sites to it in such a way to maintain the sort order using toIdentifierList.
// In module 'decimal'
function toIdentifierList(n: t,
before: Identifier.t[],
after: Identifier.t[],
creationSite: number): Identifier.t[] {
// Implements the constructPosition rules from the Logoot paper
return n.map((digit, index) => {
if (index === n.length - 1) {
return Identifier.create(digit, creationSite);
} else if (index < before.length && digit === before[index].digit) {
return Identifier.create(digit, before[index].site);
} else if (index < after.length && digit === after[index].digit) {
return Identifier.create(digit, after[index].site);
} else {
return Identifier.create(digit, creationSite);
}
});
}
Case 2: Head digits are the same, sites are different
beforePosition = [(1, 1), ...]
afterPosition = [(1, 3), ...]
Here, observe that newPosition = [(1,1), ...anything] will always satisfy newPosition < afterPosition.
More generally, if the site is used as a tiebreaker, notice that the new position could be anything that starts with the same identifier as beforePosition and will still be sorted before afterPosition. Which is why in the recursion
return cons(head1, generatePositionBetween(rest(position1), [], site));
We just pass an empty list as the second parameter.
Case 3: Head digits and sites are the same
beforePosition = [(1, 1), ...]
afterPosition = [(1, 1), ...]
If the two digits are the same, then we need to look at the subsequent digits to find an in-between position, so we just recurse on the rest.
return cons(head1, generatePositionBetween(rest(position1), rest(position2), site));
With these three cases covered, we’re able to generate new positions for inserted characters.
Staying all in sync
To synchronize between clients, “add” and “remove” events are sent as such.
namespace RemoteChange {
type t = ["add" | "remove", Char.t];
function add(char: Char.t): t {
return ["add", char];
}
function remove(char: Char.t): t {
return ["remove", char];
}
}
Here, Char.t is just an object containing a position identifier and a character. As in the case of fruit baskets, deleting a character just needs to delete by ID.
For simplicity, we always send remote changes as single character insertions or deletions. For efficiency, it would be better to batch them though that’s a simple optimization.
From abstractionland to userland
Let’s recap what we’ve created so far: a way of maintaining an ordered list of characters with unique identifiers and generate new identifiers in-between characters.
Using what we’ve seen previously, this is sufficient to represent a text document and synchronize it between clients. On the server-side, it’s actually sufficient to just store all the characters in an unordered hashtable, since the server only reads and relays ADD and DELETE operations.
Of course, on the client-side, users want more than a representation of a text document. Users want to be able to modify it with a simple interface. In my case, I am using CodeMirror as the underlying text editor, a popular open-source Javascript library.
CodeMirror has obviously no idea about CRDTs, and just stores the text content as lines of characters. This means I have to store two copies of the text: one in the text editor for client use, and one in the CRDT for synchronization use.
To interact with CodeMirror using the programming API, I can receive change events or send it patches using a EditorChange object that looks something like this:
interface EditorChange {
from: {
line: number
column: number
}
to: {
line: number
column: number
}
added: string
removed: string
}
(The actual object is a bit different but I changed it for ease of presentation)
That means we need to keep the CodeMirror editor and the CRDT in sync when any of the following four events happen:
- Remote change: insertion
- Get index of the preceding character in the CRDT
- Insert character in the CRDT
- Create a local change inserting a character at that index
- Remote change: deletion
- Get the index of a character with the same position identifier in the CRDT
- Delete that character in the CRDT
- Create a local change deleting a character at that index
- Local change: insertion at position n
- Find the nth and (n+1)th character in the CRDT
- Create a position identifier between character n and n + 1 and insert character in the CRDT
- Send out a remote insert change for that character
- Local change: deletion at position n
- Find the nth character in the CRDT
- Delete that character in the CRDT
- Send out a remote delete change for that character
I won’t go into the details of how each of these events are handled. It’s non-trivial and a lot of lines of code, but ultimately rather mechanical and I don’t think there’s a whole lot of insights to be had.
That being said, there’s 3 ways in which you could implement this, from easiest (and least performant) to hardest (and most performant).
Array of <position identifier, character>
The simplest thing you can do is to store all your characters as a linear array. When you need to search for a position identifier, use binary search. Searching for newline characters may require linear search. This is only going to scale up to a few hundred characters, since you have worst-case quadratic complexity when making large changes. However, it is perfectly reasonable to start with this as a prototype.
Array of array of <position identifier, character>
You can also split the array of characters for the whole document and have one array for each line. This should allow you to support text documents up to a few hundred lines, assuming most text documents have at most a few hundred characters per line. If you only want to build a collaborative text editor as a side project, this approach is probably fine.
Binary search tree of <position identifier, character>
The most efficient approach is to store the characters in a binary search tree. You’ll probably have to supply a custom comparator. Finding, inserting and deleting characters are all O(log(n)) operations as long as you choose an implementation that’s balanced.
You will, however, also need to augment the binary tree with order statistics. That is, you also want to be able to query for the nth character in the tree, by storing the size of the tree at each node. You might also want to be able to query for the nth newline character.
The downside, in addition to requiring a custom data structure, is that the binary tree will require additional storage per character (at the very least a left and right pointer, integer for node size) which is big given how memory hungry this approach is already.
Trie of positions
You can reuse individual positions (“digits”) in a position identifier by storing the whole thing as a trie. Of course, this is a bit more challenging than a regular trie, since you will have to deal with the site tiebreakers and removal of characters. See also TreeDoc.
(Note that in any case, can’t use a hashtable on the client since hashtables don’t provide an ordering to the keys).
Conclusion
I’m not going to pretend writing a real-time collaborative text editor is an easy project. It took me 3-4 days just to write the core of it, and an order magnitude more to write tests, make the UI nice, and add other features on top of it (e.g. seeing the other people’s cursors). It would take even more to make it resilient to failures, implement access control, etc. However, as I hope this article convinced you, there are approaches that can be fairly intuitive and the solution can be understood as a series of layers, and broken down into approachable tasks.
Thanks for reading, and let me know if you have any feedback!
Thanks to Ryan Kaplan for reading over and reviewing this blog post.
